3.7. Conductor service¶
Il coordinatore è basato su Netflix - Conductor una piattaforma gratuita e open source per l’orchestrazione dei microservizi, attraverso flussi di lavoro che definiscono le interazioni tra servizi, il progetto principale è stato forkato per permettere e gestire l’autenticazione e l’autorizzazione sull’esecuzione dei flussi e sul passaggio della stessa ai microservizi invocati dal flusso.
Nel progetto workflow-definition sono presenti le definizioni in formato json dei flussi necessari al completamento degli obiettivi del progetto.
3.7.1. Flusso principale - Amministrazione Trasparente¶
Importante
Il flusso principale necessita dei seguenti parametri di input per la sua corretta invocazione come mostrato in Tabella 3.1
Nome |
Descrizione |
Valore consigliato/default |
Può essere Vuoto? |
|---|---|---|---|
page_size |
Dimensione della pagina per il recupero delle PA |
2000 |
No |
parent_workflow_id |
Identificativo del flusso, viene valorizzato con UUID generato |
vuoto |
Si |
codice_categoria |
Se valorizzato filtra le PA che fanno parte della categoria |
vuoto |
Si |
codice_ipa |
Se valorizzato individua la singola PA |
vuoto |
Si |
crawling_mode |
Modalità base di esecuzione del crawler può assumere i valori httpStream e htmlSource |
httpStream |
No |
crawler_save_object |
Booleano indica se salvare sempre la pagina HTML |
false |
No |
crawler_save_screenshot |
Booleano indica se salvare sempre lo screenshot della pagina |
false |
No |
rule_name |
Nome della regola |
amministrazione-trasparente |
No |
root_rule |
Nome della regola di base dell’albero |
amministrazione-trasparente |
No |
execute_child |
Booleano indica se controllare le regole figlie |
true |
No |
id_ipa_from |
Identificativo numerico della PA da cui partire |
0 |
No |
connection_timeout |
Timeout in millisecondi della connessione |
60000 |
No |
read_timeout |
Timeout in millisecondi della lettura |
60000 |
No |
connection_timeout_max |
Timeout in millisecondi della connessione |
120000 |
No |
read_timeout_max |
Timeout in millisecondi della lettura |
120000 |
No |
crawler_child_type |
Modalità di esecuzione dei flussi figli può assumere i valori SUB_WORKFLOW e START_WORKFLOW |
START_WORKFLOW |
No |
rule_base_url |
URL di base del microservizio delle Regole |
URL |
No |
public_company_base_url |
URL di base del microservizio delle PA |
URL |
No |
result_aggregator_base_url |
URL di base del microservizio Aggregato |
URL |
No |
result_base_url |
URL di base del microservizio dei Risultati |
URL |
No |
crawler_uri |
URL di base del microservizio Crawler |
URL |
No |
3.7.2. Dettagli del flussso principale¶
Il primo TASK del flusso si occupa di invocare l’aggiornamento della configurazione del microservizio delle regole. Dopo aver valorizzato la variabile necessaria al controllo delle pagine elaborate, il flusso invoca il microservizio delle PA descritto in Public Sites Service e recupera le informazioni necessarie.
Il blocco recuperato contentente le informazioni di n PA viene parcellizzato in base al parametro fornito in input page_size e diviso per 10, utilizzando infine il TASK FORK/JOIN vengono eseguiti in parallello 10 istanze del flusso Rule valorizzando il parametro in input companies.
All’uscita del TASK delle PA, se il flusso è stato eseguito non per una singola PA, allora vengono rielaborati i risultati con i codici 400 e 407 con i timeout massimi ed eseguiti i flussi Crawler Result Failed.
Infine viene eseguito il TASK per elaborare la Mappa geolocalizzata dei risultati.
In Fig. 3.1 l’immagine del flusso:

Fig. 3.1 Flusso principale - Amministrazione Trasparente¶
3.7.3. Flusso per singola Amministrazione¶
Il flusso Rule Detail come mostrato in Fig. 3.2 viene eseguito per una singola PA passata come parametro in input ipa, controlla inizialmente la presenza della URL istituzionale e successivamente invoca il crawler il cui risultato viene passato al microservizio delle regole e la cui risposta è utilizzata come input al Task dei risultati
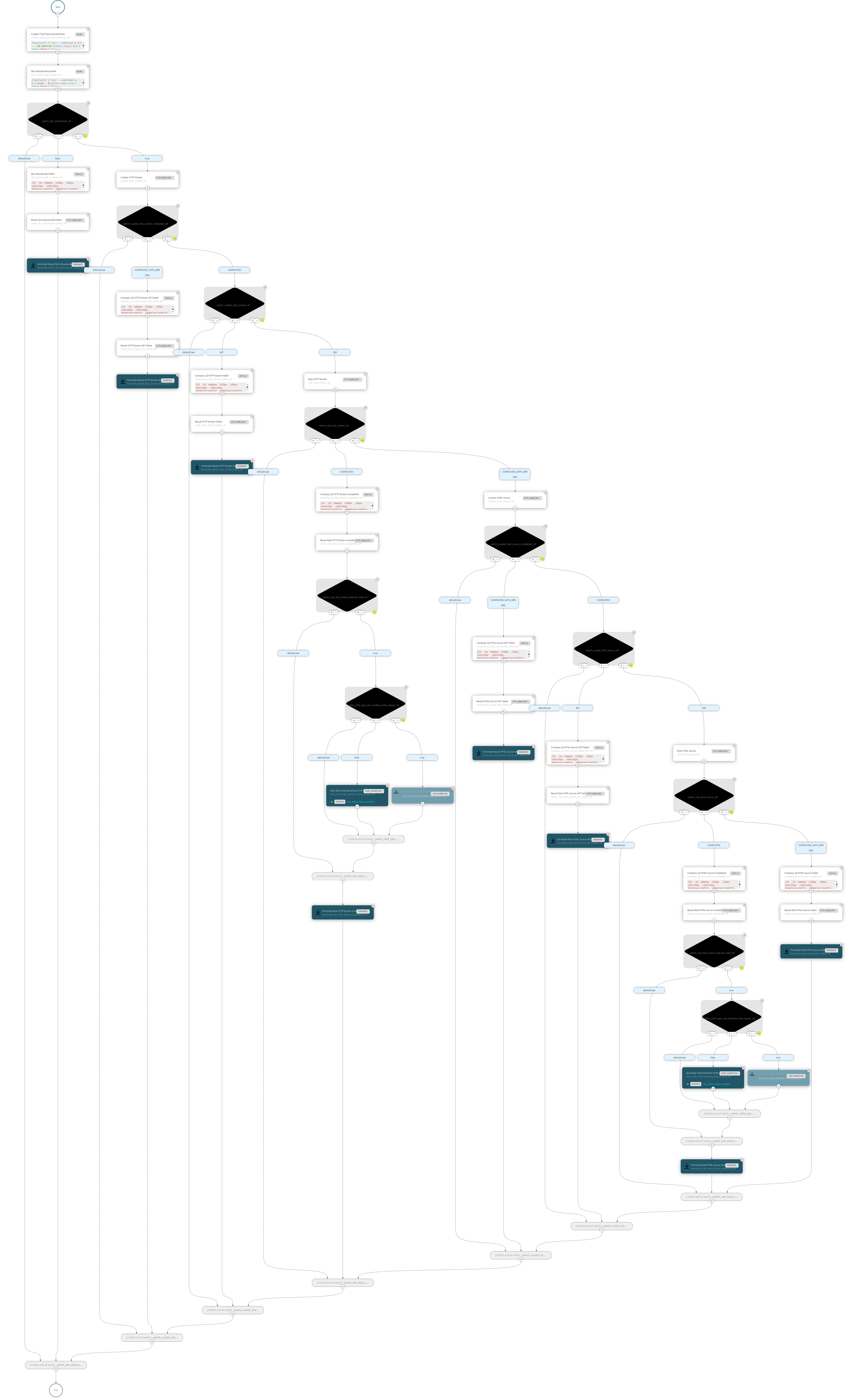
Fig. 3.2 Flusso per singola Amministrazione¶